
Module 2: Terminology & Concepts
The CRQ Open Education Toolkit from CyberRiskModels.com includes a spreadsheet for conducting vulnerability data analysis. This module will introduce you to this resource and explain the process for analyzing your vulnerability data. (See the Additional Resources section.)
Vulnerability data analysis is an essential component of risk analysis in cybersecurity. The goal is to identify those vulnerabilities most likely to be leveraged against you in a cyber-attack. The purpose of vulnerability data analysis is to prioritize the remediation of vulnerabilities based on their potential impact on critical assets and processes.
Common Vulnerability Enumeration (CVE) scores provide a valuable metric for assessing the severity of a vulnerability to an asset as assigned by the vendor, but the score itself has no relevance to your organization.
To conduct an effective vulnerability data analysis, organizations must understand the relationship between vulnerability, the likelihood of an attack, and the potential impact on critical assets. This requires a thorough understanding of the organization’s infrastructure, critical assets, and processes.
Our Process for Analyzing Vulnerability Data
The process of analyzing vulnerability data is straightforward. It involves obtaining the data, organizing it meaningfully, tagging vulnerabilities for key characteristics, and extracting statistics.
Once vulnerability data has been analyzed, you can proceed with generating charts,
associate vulnerabilities to assets or processes, quantify the threat, estimate the likelihood vulnerabilities might be leveraged against you, and develop recommendations.

Figure 10 Vulnerability Data Analysis
Collecting Vulnerability Data
The first step in the vulnerability analysis process is to collect your vulnerability data. This involves using a vulnerability scanning tool to identify vulnerabilities in systems and applications. These tools can be run manually or automatically and scan for vulnerabilities in both on-premises and cloud-based systems. Once vulnerability data has been collected, it can be exported to Excel for analysis.
Tagging the Data
The vulnerability description is a critical piece of information that helps organizations understand the nature of a vulnerability, its source, and how a threat actor can exploit it. This text field provides details on the vulnerability that may not be captured in the CVSS score alone. For this reason, it is the key component of vulnerability data analysis.
The description field contains standard text (keywords) to help organizations understand the nature of the vulnerability. The description may include words such as “elevation of privileges” and “code execution,” as well as named exploits such as “denial of service” and “man-in-the-middle” attacks.
By identifying these keywords in the vulnerability description field, organizations can gain a much deeper understanding of the threat than what can be imagined from the CVSS score alone. For example, a vulnerability with a high CVSS score may not be a priority to the organization if it requires a threat actor to have physical access to the system. In contrast, a vulnerability with a lower CVSS score that allows remote code execution may be a much higher priority to the organization.
Grouping by Tags
There are several ways to group vulnerabilities, including vendor, software, protocol, and attack-specific characteristics. Each category requires different keyword selection strategies to group vulnerabilities effectively. Each group represents a set of keywords. You are encouraged to use several groups of keywords for a single collection of vulnerability data and thereby gain deeper insight into the data.
When grouping vulnerabilities by vendor, software, protocol, or attack type, it is important to select keywords specific to that category. This means using vendor-specific keywords, software-specific keywords, protocol-specific keywords, or attack-related keywords.
Vendor Specific Keywords
When grouping vulnerabilities by vendor, it is important to select keywords that are specific to that vendor. For example, if an organization is using software developed by Microsoft, keywords such as “Microsoft,” “Windows,” and “Office” may be used to group vulnerabilities.
Other vendor-specific keywords may include the name of the product, the version number, and any other unique identifiers. By selecting vendor-specific keywords, organizations can quickly identify vulnerabilities that are specific to the products they are using.
What are your vendor keywords?
|
|
|
|
|
|
|
|
|
|
Software Keywords
When grouping vulnerabilities by software, it is important to select keywords that are specific to that software. For example, if an organization is using a web application developed with PHP, keywords such as “PHP,” “Apache,” and “MySQL” may be used to group vulnerabilities.
Other software-specific keywords may include the name of the software, the version number, and any other unique identifiers. By selecting software-specific keywords, organizations can quickly identify vulnerabilities that are specific to the applications they are using.
What are your software keywords?
|
|
|
|
|
|
|
|
|
|
Protocol Keywords
When grouping vulnerabilities by protocol, it is important to select keywords that are specific to that protocol. For example, if an organization is using the HTTP protocol, keywords such as “HTTP,” “HTTPS,” and “SSL/TL” may be used to group vulnerabilities.
Other protocol-specific keywords may include the name of the protocol, the version number, and any other unique identifiers. By selecting protocol-specific keywords, organizations can quickly identify vulnerabilities specific to the protocols they use.
What are your protocol keywords?
|
|
|
|
|
|
|
|
|
|
Attack Related Keywords
Selecting keywords related to common attack methods is important when grouping vulnerabilities by attack type. For example, keywords such as “SQL injection,” “Cross-site scripting,” and “Buffer overflow” may be used to group vulnerabilities that are commonly exploited using these methods.
Other attack-related keywords may include the exploit’s name, the attack type, and other unique identifiers. By selecting attack-related keywords, organizations can quickly identify vulnerabilities commonly exploited using specific attack methods.
These keywords will help you find exploitable vulnerabilities, those vulnerabilities most likely to be leveraged against you in a cyber-attack.
What are your attack keywords?
|
|
|
|
|
|
|
|
|
|
Using Wild*Cards
As you work with vulnerability data, you will notice that not all vendors use the same terms to describe the same vulnerability condition. For example, you will see “Denial of Service,” “denial-of-service,” or “DoS.” All three of these expressions refer to the same vulnerability condition.
One way to deal with this situation is to use all three variations, which is unsatisfactory when all three terms appear in charts and tables. Rather than manually consolidate to produce a cleaner table or chart, consider using wild*cards. For example, “denial*service” will correctly select and tag the first two expressions in our earlier example.
Linking Keywords to Attack Stages
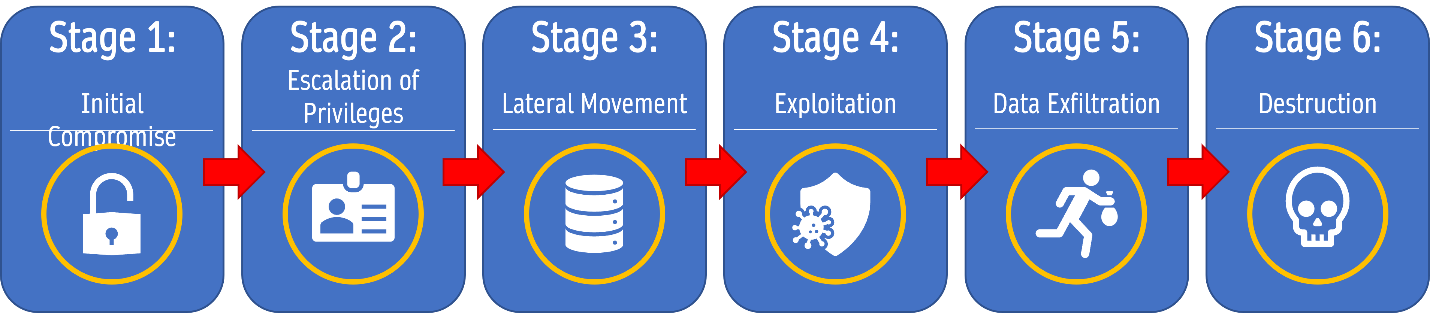
Cybercriminals use various techniques to gain access to sensitive data and systems, and understanding the attack sequence is essential for organizations to protect themselves. We will explore the basic attack sequence, which consists of six stages: initial compromise, escalation of privileges, lateral movement, exploitation, data exfiltration, and destruction.
The vulnerability description field contains keywords at each stage of the attack sequence, which can be used to correlate the vulnerability with where it is most likely to be leveraged within a typical attack sequence.
MITRE ATT&CK Model
The MITRE ATT&CK model is a comprehensive framework for understanding and categorizing the tactics, techniques, and procedures (TTPs) used by attackers during a cyber-attack. Developed by the MITRE Corporation, the model has become widely adopted by cybersecurity professionals to better understand and defend against cyber threats. We will discuss the history of the MITRE ATT&CK model, the difference between tactics and techniques, and how the model is useful in understanding advanced persistent threats (APTs) and the attack cycle.
MITRE ATT&CK History
The MITRE ATT&CK model was first introduced in 2013 to help organizations better understand the tactics and techniques used by advanced persistent threats (APTs). The model was developed by MITRE Corporation, a non-profit organization that operates federally funded research and development centers (FFRDCs) in support of the U.S. government.
The initial version of the MITRE ATT&CK model included 12 categories of attack techniques, each with several sub-techniques. Since then, the model has been expanded and updated to include over 200 techniques across 12 categories, making it one of the most comprehensive frameworks for understanding cyber-attacks.
Tactics vs. Techniques
Before diving into the specifics of the MITRE ATT&CK model, it is important to understand the difference between tactics and techniques. In cyber-attacks, tactics refer to an attacker’s overall goals or objectives, while techniques refer to the specific methods used to achieve those goals.
For example, attackers commonly use a tactic to gain access to a target system. The techniques used to achieve this goal might include exploiting a vulnerability in the system, using stolen credentials, or tricking a user into downloading malware.
By mapping keywords to attack stages, you are identifying the exploitable vulnerabilities and identifying where in the attack sequence they are most likely to be used.
Typical Attack Sequence Overview
- Initial Compromise: The first stage of the attack sequence is the initial compromise, which involves the attacker gaining access to the target system or network. This can be achieved through various methods, such as phishing emails and social engineering. Once the attacker gains access, they can explore the system and identify potential targets for further attacks.
- Escalation of Privileges: The next stage of the attack sequence is the escalation of privileges, which involves the attacker gaining administrative access to the system or network. Once the attacker has administrative access, they can move laterally through the network and gain access to additional systems and data.
- Lateral Movement: The third stage of the attack sequence is lateral movement, which involves the attacker moving laterally through the network and gaining access to other systems and data. This can be achieved through various techniques, such as exploiting software or hardware vulnerabilities or using stolen credentials. Once the attacker has access to other systems and data, they can begin to identify sensitive data and potential targets for exploitation.
- Exploitation: The fourth stage of the attack sequence is exploitation, which involves the attacker using various techniques to exploit vulnerabilities in systems and software to gain access to sensitive data. This can be achieved through different techniques like SQL injection, cross-site scripting, or buffer overflow attacks. Once the attacker gains access to sensitive data, they can exfiltrate it for later use or destruction.
- Data Exfiltration: The fifth stage of the attack sequence is data exfiltration, which involves the attacker stealing sensitive data from the target system or network. This can be achieved through various methods, such as using malware to exfiltrate data or remote access tools to copy data to a remote server. Once the attacker has stolen the data, they can use it for various purposes, such as selling it on the dark web or using it for extortion.
- Destruction: The final stage of the attack sequence is destruction, which involves the attacker destroying data or systems to cover their tracks or cause damage to the target organization. This can be achieved through various methods, such as using malware to delete data or remote access tools to delete critical system files. Once the attacker has destroyed the data or systems, it can be difficult for the target organization to recover, and the attacker can continue to cause damage or steal data.
Some Common Attack Related – Exploitable – Keywords
Here are some examples of keywords. Each data set will have a unique set of keywords. This is why you visually inspect the data first to identify the keywords within the data set you are working with.
Sample keywords: Response smuggling, malicious files, authentication bypass, malicious SML document, cross-site scripting, upload arbitrary files, denial of service or DoS, code execution, elevation of privilege, privilege escalation, information disclosure, arbitrary file deletion, arbitrary code, all the attacker to decrypt, bypass authentication, delete files, disclosure of sensitive information, default credentials, write access to a database, HTTP request smuggling, Lof4j, spoofing, run with root permissions.
Now, consider how these keywords match up to the first three stages of an attack.
|
Initial Access |
Privilege Escalation |
Lateral Movement |
|
Code execution, arbitrary code, RCE (short for remote code execution), injection, spectre, Log4j, XSS (short for cross-site scripting), MiTM (short for man-in-the-middle) |
Authentication, privilege, default, anonymous, AutoLogon, access control |
SMB, information disclosure, SNMP, SSH |
Table 1 Keywords and Attach Phases
Advanced Persistent Threats (APTs) and the Attack Cycle
APTs) are a type of cyber-attack characterized by a long-term approach to compromising a specific target. APTs often involve multiple stages and techniques and can be challenging to detect and defend against.
The MITRE ATT&CK model is particularly useful in understanding APTs because it breaks down the attack cycle into discrete phases, each with its own set of techniques. By understanding the techniques attackers use at each phase of the attack cycle, organizations can better defend against APTs and other advanced threats.
For example, during the Initial Access phase of an APT attack, attackers might use spear phishing or exploit a vulnerability in a web application to gain access to a target system. By understanding these techniques, organizations can implement user education and vulnerability patching measures to reduce the likelihood of a successful attack.
During the Lateral Movement phase of an APT attack, attackers might use pass-the-hash or remote desktop protocol (RDP) to move laterally within a target network. By understanding these techniques, organizations can implement measures such as network segmentation and access controls to limit attackers’ ability to move laterally within a network.
Finally, during the Impact phase of an APT attack, attackers might use data encryption or denial-of-service (DoS) attacks to disrupt or damage a target system. By understanding these techniques, organizations can implement measures such as data backups and disaster recovery plans to minimize the impact of an attack.
By breaking down the attack cycle into discrete phases and techniques, the model provides organizations with a comprehensive view of the threat landscape and enables them to implement effective defenses against advanced persistent threats and other types of cyber-attacks. As the threat landscape continues to evolve, the MITRE ATT&CK model plays a critical role in the fight against cybercrime.
